La Inteligencia Artificial y sus aplicaciones más disruptivas en la actualidad (parte 2)

“La verdad os hará libres; la mentira os hará creyentes”: Pepe Rodríguez (filósofo, psicólogo y escritor español)
🖋 David Moisés Terán Pérez *
Buenos días estimadas(os) lectoras(es) de esta columna invitada. Como ya es nuestra costumbre, tengan un grandioso, feliz, productivo y extraordinario martes. En esta ocasión continuaremos desarrollando contenido para la saga que se inició la semana pasada, con un tema bastante interesante y sumamente actualizado: “La Inteligencia Artificial (IA)”. Comenzamos: En esta ocasión, exploraremos el entrenamiento a gran escala, de los modelos generativos sobre datos de video.
En concreto, se están entrenando modelos de difusión condicional de texto de manera conjunta sobre vídeos e imágenes de duración, de resolución y de relación de aspectos sumamente variables. Se está aprovechando una arquitectura transformadora, que opera en lugares espacio-temporales de códigos latentes de imágenes y de videos. El modelo más grande: SoraAI™, es capaz de generar un minuto de vídeo de alta fidelidad. Los resultados sugieren que escalar modelos de generación de video, es un camino bastante prometedor, hacia la construcción de simuladores de propósito general del mundo físico.
Existe un informe técnico que se centra en un método para convertir datos visuales de todo tipo, en una representación unificada que permita el entrenamiento a gran escala de modelos generativos y la evaluación cualitativa de las capacidades y de las limitaciones de SoraAI™.
Pero, ¿qué es SoraAI™? De acuerdo a lo que vimos la semana pasada, SoraAI™ es un generador de arte con Inteligencia Artificial (IA), que permite crear personajes de Anime y muchas cosas más. SoraAI™ es una aplicación móvil gratuita, que utiliza la tecnología de la inteligencia artificial (IA), para generar arte a partir de descripciones textuales. Permite a los usuarios, crear imágenes de una amplia gama de temas, incluyendo personajes de anime, paisajes, criaturas fantásticas, y mucho, mucho más. Entre sus características principales y más importantes, se encuentran las siguientes:
- Fácil de usar: Simplemente, escriba una descripción de la imagen que desea crear, y SoraAI™ la generará en cuestión de segundos de manera excepcional.
- Potente: Esto significa que SoraAI™, puede crear imágenes de alta calidad con una gran cantidad de detalles, que incluso un humano, podría pasar inadvertidos.
- Versátil: Puede usarse para crear una amplia gama de imágenes, desde personajes de anime, hasta paisajes realistas de alta definición y detalle.
- Personalizable: Puede ajustar la configuración de la generación de imágenes, para obtener resultados más específicos.
- Gratuita: La aplicación es gratuita, y no requiere de ninguna suscripción. SoraAI™, es una herramienta poderosa para artistas, para diseñadores, y para cualquier persona que quiera crear imágenes creativas e imaginativas. También es una excelente manera de aprender sobre el uso y las aplicaciones de la inteligencia artificial (IA), y cómo se puede usar para crear arte.
Aquí hay algunos detalles adicionales sobre SoraAI™, que pueden ser útiles para entender y comprender mejor sus aplicaciones, y su funcionamiento:
- Tecnología: La aplicación SoraAI™, utiliza una tecnología de inteligencia artificial (IA) llamada “aprendizaje automático”, para generar imágenes. El “aprendizaje automático”, es un tipo de inteligencia artificial (IA), que permite a las computadoras aprender por sí mismas, sin ser programadas explícitamente.
- Datos: La aplicación SoraAI™, se entrena con un conjunto de datos masivo de imágenes y de texto. Este conjunto de datos, incluye imágenes de anime, paisajes, criaturas fantásticas, y muchas cosas más.
- Comunidad: La aplicación SoraAI™, tiene una comunidad activa de usuarios que comparten sus creaciones en línea. Puede encontrar inspiración y consejos de otros usuarios en la comunidad de SoraAI™.
Por otra parte, desde el punto de vista de su desarrollo y de la fase teórica que la sustenta, muchos trabajos anteriores han estudiado el modelado generativo de datos de video, utilizando una variedad de métodos, incluidas las redes recurrentes [(Srivastava; Mansimov & Salakhudinov, 2015); (Chiappa, et. al., 2017); (Ha & Schmidhuber, 2018)], las redes generativas adversarias [(Vondrick; Pirsiavash & Torralba, 2016); (Tulyakov, et. al., 2018); (Clark; Donahue & Simonyan, 2019); (Brooks, et. al., 2022)]; los transformadores autorregresivos [(Yan, et. al., 2021); (Wu, et. al., 2022)], y los modelos de difusión [(Ho, et. al., 2022); (Gupta, et. al., 2023); (Vaswani, et. al., 2017)]. Estos trabajos a menudo se centran en una categoría limitada de datos visuales, en videos más cortos, y/o en videos de un tamaño fijo. SoraAI™, es un modelo generalista de datos visuales: Puede generar vídeos e imágenes de diversas duraciones, relaciones de aspecto y resoluciones, hasta un minuto completo de vídeo de alta definición.
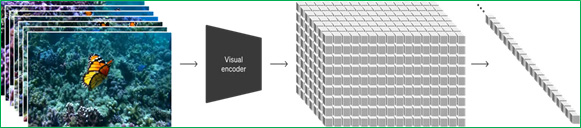
Ahora, la pregunta es: ¿Cómo convertir datos visuales en parches? Esto se hace inspirándose en grandes modelos de lenguaje, que adquieren capacidades generalistas mediante el entrenamiento con datos a escala de la Internet [(Blattmann, et. al., 2023); (Brown, et. al., 2020)].
El éxito del paradigma de los modelos de lenguaje grande (LLM), se debe en parte al uso de tokens que unifican elegantemente diversas modalidades de texto: Como el código, las matemáticas, y varios lenguajes naturales. En este momento, considérense cómo los modelos generativos de datos visuales, pueden heredar tales beneficios. Mientras que los modelos de lenguaje grande (LLM), tienen tokens de texto, SoraAI™, tiene parches visuales.
Anteriormente se ha demostrado que los parches son una representación efectiva para modelos de datos visuales [(Dosovitskiy, et. al., 2020); (Arnab, et. al., 2021); (He, et. al., 2022); (Dehghani, et. al., 2023)]. Todas estas referencias, se convierten en el Estado del Arte o en el Estado del Conocimiento de este tema, lo que le da aún más, un valor agregado sustancial al conocimiento de este tema.
Encontramos que los “parches”, son una representación altamente escalable y efectiva para entrenar modelos generativos en diversos tipos de videos e imágenes, tal como puede verse la Fig. 1.
La próxima semana, continuaremos haciendo una descripción de esta interesante y sorprendente herramienta. Espero que los(as) lectores(as) de esta columna invitada semanal en La Verdad Hidalgo ya estén descargando la aplicación a sus equipos de cómputo, con la finalidad de aprender su uso, y muy pronto, estén desarrollando sus propias creaciones, para que las compartan. Y, como siempre, reciban un cordial saludo, y un gran abrazo, desde la cada vez más Hermosa Bahía de Banderas (Puerto Vallarta y la Riviera Nayarit). (Continuará…)
Referencias:
Arnab, Anurag, et. al. (2021). Vivit: A video vision transformer. Proceedings of the IEEE/CVF International Conference on Computer Vision.
Blattmann, Andreas, et. al. (2023). Align your latents: High-resolution video synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Brooks, Tim, et. al. (2022). Generating long videos of dynamic scenes. Advances in Neural Information Processing Systems, 35: 31769-31781.
Brown, Tom, et. al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33: 1877-1901.
Chiappa, Silvia, et. al. (2017). Recurrent environment simulators. arXiv preprint arXiv:1704.02254.
Clark, Aidan; Donahue, Jeff & Simonyan, Karen. (2019). Adversarial video generation on complex datasets. arXiv preprint arXiv:1907.06571.
Dehghani, Mostafa, et. al. (2023). Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution. arXiv preprint arXiv:2307.06304.
Dosovitskiy, Alexey, et. al. (2020). An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Gupta, Agrim, et. al. (2023). Photorealistic video generation with diffusion models. arXiv preprint arXiv:2312.06662.
Ha, David & Schmidhuber, Jürgen. (2018). World models. arXiv preprint arXiv:1803.10122.
He, Kaiming, et. al. (2022). Masked autoencoders are scalable vision learners. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Ho, Jonathan, et. al. (2022). Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303.
Rombach, Robin, et. al. (2022). High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Srivastava, Nitish; Mansimov, Elman & Salakhudinov, Rusland. (2015). Unsupervised learning of video representations using lstms. International Conference on Machine Learning. PMLR.
Tulyakov, Sergey, et. al. (2018). Mocogan: Decomposing motion and content for video generation. Proceedings of the IEEE conference on computer vision and pattern recognition.
Vaswani, Ashish, et. al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Vondrick, Carl; Pirsiavash, Hamed & Torralba, Antonio. (2016). Generating videos with scene dynamics. Advances in Neural Information Processing Systems, 29.
Wu, Chenfei, et. al. (2022). Nüwa: Visual synthesis pre-training for neural visual world creation. European Conference on Computer Vision. Cham: Springer Nature Switzerland.
Yan, Wilson, et. al. (2021). Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157.