La Inteligencia Artificial y sus aplicaciones más disruptivas en la actualidad (parte 4)

“La verdad os hará libres; la mentira os hará creyentes”: Pepe Rodríguez (filósofo, psicólogo y escritor español)
🖋 David Moisés Terán Pérez *
Buenos días estimadas(os) lectoras(es) de esta columna invitada. Como ya es nuestra costumbre, deseo que tengan un grandioso, feliz, productivo y extraordinario martes. En esta ocasión, continuaremos desarrollando contenido para la saga que se inició hace ya tres semanas, con un tema bastante interesante, perentorio por conocer, por dominar y por aprender, así como sumamente actualizado: “La Inteligencia Artificial (IA) aplicada a la Educación”.
En esta ocasión, continuaremos con la explicación del funcionamiento de los modelos generativos basados en datos, para generar video a través de éstos; es decir, continuaremos explicando el formato de operación de SoraAI™, y también continuaremos ofreciendo un Estado del Arte o Estado del Conocimiento sobre este tema, a través de las referencias que se han incluido —tanto en este, como en los anteriores artículos—. Esto representa una ventaja competitiva importante, porque el(la) lector(a) interesado(a) en ahondar sobre el tema, podrá hacerlo de manera autónoma y bien fundamentada, ya que todas las referencias están validadas y actualizadas. Comenzamos:
USO DE INDICACIONES (PROMPTS) CON IMÁGENES Y CON VÍDEOS
Todos los resultados vistos en los artículos anteriores, muestran ejemplos de conversión de texto a video. Pero a SoraAI™, también se le pueden solicitar otras entradas, como imágenes y/o vídeos preexistentes. Esta capacidad le permite a SoraAI™, realizar una amplia gama de tareas de edición de imágenes y de videos como: Crear videos en un ciclo (bucle) perfecto, animar imágenes estáticas, extender videos hacia adelante o hacia atrás en el tiempo, etcétera.
ANIMANDO IMÁGENES CON DALL·E
Es decir, SoraAI™, es capaz de generar videos, siempre que se tenga una imagen y/o un mensaje como entrada. El(la) lector(a), puede ver un ejemplo generado a partir de las imágenes que DALL·E 2 (Meng, et. al., 2021), y que DALL·E 3 (Betker, et. al., 2023), muestran en la Fig. 1, con el video que puede observarse en la siguiente liga: https://www.youtube.com/watch?v=ESfMSGuGa_Q&t=16s&ab_channel=ElMundo

Fuente: https://openai.com/research/video-generation-models-as-world-simulators
AMPLIAR VÍDEOS GENERADOS
Puede afirmarse que SoraAI™, también es capaz de extender vídeos, ya sea hacia adelante o hacia atrás en el tiempo. Por ejemplo, cuando se quieren mostrar videos que se extendieron hacia atrás en el tiempo a partir de un segmento de un video generado; como resultado se obtiene que cada uno de esos videos, comienza de manera diferente a los demás, pero los cuatro videos conducen al mismo final. Por lo que, es posible usar este método, para extender un video hacia adelante y hacia atrás, para producir un bucle infinito sin interrupciones.
EDICIÓN DE VIDEO A VIDEO
Los modelos de difusión, han habilitado una gran cantidad de métodos para editar imágenes y videos, a partir de indicaciones de texto. Esta técnica permite a SoraAI™, transformar los estilos y los entornos de videos de entrada con disparo (shot) cero. Es decir, sin latencia.
CONECTANDO DIVERSOS VÍDEOS
También es posible usar SoraAI™, para interpolar gradualmente entre dos, tres, o más videos de entrada, creando transiciones perfectas entre los videos, que contienen temas y composiciones de escenas completamente diferentes. Es posible entonces, que los vídeos del centro, se interpolan entre los vídeos correspondientes a la izquierda y a la derecha en una simulación. Eso vuelve sumamente realista la experiencia de generación.
CAPACIDADES DE GENERACIÓN DE IMÁGENES
También SoraAI™, es capaz de generar imágenes. Esto se hace, organizando “parches de ruido gaussiano” en una cuadrícula espacial, con una extensión temporal de un cuadro. El modelo puede generar imágenes de tamaños variables, con una increíble y asombrosa resolución de hasta 2 048*2 048 pixeles (ver la Fig. 2). Ahora, se explica qué es, en qué consiste y para qué sirven “los parches de ruido gaussiano”:
- Los parches de ruido gaussiano: Son una técnica comúnmente utilizada en el procesamiento de imágenes, para simular el ruido que puede ocurrir en imágenes digitales. El ruido gaussiano, es un tipo de ruido aleatorio que sigue una distribución gaussiana —también conocida como distribución normal—. La idea detrás de los parches de ruido gaussiano, es agregar una pequeña cantidad de ruido gaussiano a ciertas regiones de una imagen, en lugar de aplicarlo a toda la imagen. Esto puede ser útil en situaciones donde se quiere simular el ruido que afecta solamente a ciertas partes de una imagen, por ejemplo, áreas de baja iluminación, o áreas con cierto tipo de textura. Los parches de ruido gaussiano se generan mediante la adición de valores aleatorios extraídos de una distribución gaussiana a los píxeles de la región seleccionada en la imagen. La intensidad del ruido, puede ajustarse según sea necesario, lo que permite controlar el grado de distorsión que se quiere agregar a la imagen. Esta técnica es comúnmente utilizada en la investigación y en el desarrollo de algoritmos de procesamiento de imágenes, para probar su robustez frente al ruido y mejorar su desempeño en condiciones realistas. También puede ser utilizada en aplicaciones de restauración de imágenes, para entrenar modelos de aprendizaje automático en la eliminación de ruido gaussiano (Smith, 2020). Y esta distribución normal se calcula a través de la siguiente expresión:
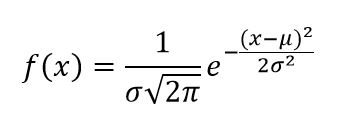
En donde:
f(x) es la función de densidad de probabilidad.
x es el valor de la variable aleatoria.
µ es la media aritmética.
σ es la desviación estándar.
e es la base del logaritmo natural (aproximadamente 2.71828).

Fuente: https://openai.com/research/video-generation-models-as-world-simulators
Increíble imagen del tigre, obtenida a través de la Inteligencia Artificial. Amables lectores(as) de esta Columna Invitada, la próxima semana, continuaremos desarrollando contenido para este disruptivo tema. Espero que ya hayan descargado de manera gratuita, la versión de SoraAI™, de la liga compartida en el artículo de la semana pasada, para que comiencen a utilizar la herramienta. Y, una vez más, reciban un afectuoso saludo desde la Hermosísima Bahía de Banderas (Puerto Vallarta y la Riviera Nayarit). (Continuará…)
Referencias:
Betker, James, et. al., (2023). Improving image generation with better captions. Computer Science. Recuperado de: https://cdn.openai.com/papers/dall-e-3. pdf 2.3 8 (Consultado en Marzo del 2024).
Meng, Chenlin, et. al., (2021). Sdedit: Guided image synthesis and editing with stochastic differential equations. Recuperado de: https://arXivpreprintarXiv:2108.01073 (Consultado en Marzo del 2024).
Smith, J. (2020). “Parches de ruido gaussiano en el procesamiento de imágenes digitales”. En: Proceedings of the International Conference on Image Processing (ICIP), p.p. 100-105. Nueva York, NY: USA/IEEE.






